I’ve been building with Claude Code long enough that a pattern has emerged that I didn’t plan. I went to write it down as a design doc and realized it wasn’t a design — it was an autopsy. The framework exists because I kept hitting the same failure modes and had to solve them. This is the map of what came out.
The honest framing: this is descriptive, not prescriptive. I’m not saying “here’s how you should structure your AI-assisted work.” I’m saying “here’s the structure that showed up when I looked at how I was actually working.”
The stack
Five layers, each one solving for something the layer above can’t handle on its own.
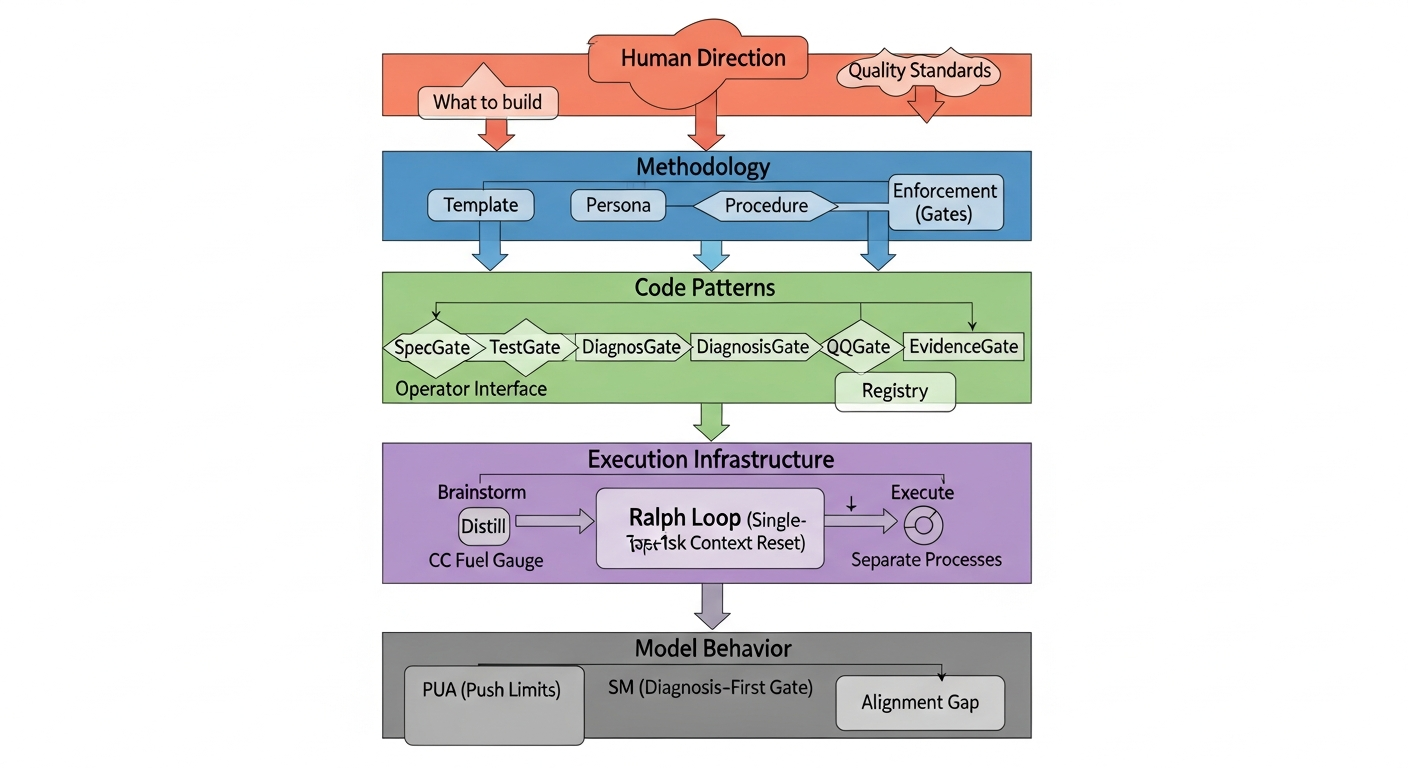
I’ll go layer by layer and explain where each piece came from and what problem it solved.
Layer 1: Human Direction (not a layer you can delegate)
The top of the stack is the one thing I can’t automate. Not because the technology doesn’t exist, but because the answers don’t exist until I think through them. What am I building, and why? Whose problem am I solving? From what angle do I want to approach it?
The quality standard at this layer is asymmetric: if I’m citing someone else’s work, I need a reference. If I’m making my own empirical claim, I need an experiment. That distinction was prompted by something that kept happening — I’d make a claim that felt obvious, the model would echo it back confidently, and I’d publish it without ever checking. Some of those claims were wrong.
Everything below this layer is infrastructure for executing the decision made here. None of it can substitute for the decision.
Layer 2: Methodology — Template, Persona, Procedure, Enforcement
This is where most of the concrete tooling lives. Four components that I originally treated as separate ideas, then realized were facets of the same thing.
Template is the spec that doubles as QC criteria. When I wrote blog.md (the style guide this post is written to), I was doing two things at once: telling the builder what to produce, and giving the auditor a ruler to measure against. The independence matters. If the builder and auditor are both reasoning from the same template, “does this pass?” becomes an answerable question rather than an aesthetic argument.
Persona constrains how the model generates, not what it generates. The TheEditor persona — borrowed and extended from Spina’s ClaudeCodeTools (184 stars) — reads articles as a critical peer, not a helpful assistant. That shift in perspective alone catches different classes of problem. A helpful assistant explains why the questionable claim might be fine. A critical peer flags it and moves on.
Procedure is the sequence. Not just “do QC” but “do QC in this order, with these criteria, on this subset.” The blog publication pipeline from from-framework-to-published is a worked example: Wave 1 format-checks already-published articles, Wave 2 does semantic QC on drafts being promoted, Wave 3 handles new articles. Each wave has a different focus because different artifacts have different failure modes.
Enforcement is what makes procedure not just a suggestion. The git pre-commit hook that blocks pushes without qc: passed in frontmatter isn’t there because I’m undisciplined. It’s there because “I’ll always remember to QC before pushing” is a resolution, and resolutions erode. A physical block doesn’t.
The connecting principle across all four: externalize the claim before acting. Design first (externalize intent), test first (externalize success criteria), diagnosis first (externalize root cause). I found I could trace almost every failure in my AI-assisted work to a step where I’d acted without externalizing first — jumped to implementation before I’d written what done should look like, tried a fix before I’d written down why I thought the bug was where I thought it was.
Layer 3: Code Patterns — Operator, Registry, Pipeline, Gate
This layer emerged from building the medical AI eval pipeline — a multi-step evaluation system for a medical AI application. I needed to generate clinical questions, score responses across four dimensions, filter by threshold, run pairwise comparisons, and audit the whole thing with an independent judge.
The naive approach was a script with function calls. The problem: every function had its own signature. Some took file paths, some took dataframes, some took the result of the previous call directly. Swapping one piece required tracing dependencies through multiple call sites.
The operator pattern forces a uniform interface: every step is run(storage, in_key, out_key). Storage is a shared dict. Steps read from a key, write to a key, don’t know about each other’s internals. To swap the generator, you swap the operator registered under "generator". The rest of the pipeline doesn’t change.
This isn’t a novel idea — it’s the same design as Luigi, Prefect, and every other pipeline framework. What took me a while to see is that it emerges naturally from the methodology layer. If procedure is your sequence of operators and gates, and if gates need to be able to block execution, you need a uniform interface for both content operators and gate operators. The operator pattern is what “procedure” looks like when you code it.
The gate operators are the methodology layer instantiated in code:
SpecGate— blocks if no spec exists before implementation beginsTestGate— blocks if tests don’t passDiagnosisGate— blocks if no written diagnosis before fix attemptQCGate— blocks if QC hasn’t signed offEvidenceGate— blocks if a claim has no citation or experiment
The pipeline-ops repo is 177 lines and 24 passing tests. The pattern extracted cleanly from the eval scripts.
On validation: the eval pipeline gave me construct validity evidence for the evaluation step specifically. The DimensionEvaluator (which scores responses across four quality dimensions) shows H1 p=0.0205 and H2 p=0.0135, with a dose-response gradient — higher-quality responses get higher scores, lower-quality ones get lower scores, and the ordering is consistent. That’s not proof the framework is correct. It’s proof that one operator does what it claims to do.
One other thing I learned building this: I stole the interface, not the code. I looked at how DataFlow structured its pipeline operators, adopted that design, and wrote my own implementation from scratch, then ran experiments to confirm the design worked for my use case. The code I borrowed ran nowhere. The design pattern ran everywhere.
Layer 4: Execution Infrastructure — Context Management and Independence
This layer is about a failure mode I hit repeatedly before naming it: the brainstorm-is-training-execution-is-inference problem.
Brainstorming with an LLM is training-like: exploratory, error-tolerant, high-volume. Executing a task is inference-like: precision-dependent, context-sensitive, where the wrong prior can send you in circles for hours. When you do both in the same session, you’re doing inference with training data still attached.
The fix is phase separation. Brainstorm until you have a clear direction. Distill the session into a brief — not a summary (which preserves the dead ends in miniature) but a selective extraction that keeps only conclusions. Execute in a clean session that starts from the brief.
The Ralph loop is the same idea applied within a single task: after each cycle, reset context. Don’t accumulate conversation history across debugging attempts or implementation rounds. Each cycle gets fresh context and the distilled output of the previous cycle.
cc-fuel-gauge monitors context size and signals when you’re approaching the degradation threshold — when it’s time to distill and reset before the context gets so large that execution quality degrades. The context-degradation-theory post covers the mechanism.
The independence mechanism is for QC specifically. An auditor running in the same session that produced the content has already been primed by the production context. It’s seen the author’s reasoning, the rejected alternatives, the “actually let me try this instead.” A genuinely independent QC agent starts from the spec and the artifact, nothing else. The claude -p flag (non-interactive, single-shot) and Docker isolation are what make that independence physical rather than aspirational.
Layer 5: Model Behavior — PUA, SM, and the Alignment Gap
This layer is honestly the least formalized. It’s more observations about how models fail than a coherent system.
PUA (7.8K stars on GitHub) addresses one failure mode: the model gives up too early or produces analysis without delivery. The plugin uses persistent pressure to force the model to exhaust more solution paths before concluding. In i-ab-tested-pua-plugin, I ran a 3-scenario A/B test and found that PUA works — in most cases. Its blind spot is overcaution. The scenario where it failed (S2, 0/3 correct fix rate) involved a model that had correctly identified the root cause but then refused to act because fixing the bug would fail tests that asserted the bug’s existence. PUA detects giving up. It doesn’t detect “I’ve analyzed this perfectly and am now paralyzed by its implications.”
SM (the structured diagnosis approach) fills that specific gap. Requiring a one-line diagnosis before any edit — [Diagnosis] The problem is ___, because ___ [evidence type] — closes the gap from 0/3 to 2/3 on the failure scenario. The proposed mechanism: writing the diagnosis creates commitment. Analysis can stay internal and produce no output. A written diagnosis makes inaction cognitively harder.
I want to be clear about what SM is in the stack: it’s not an independent concept. It’s DiagnosisGate — the code pattern layer’s enforcement of “diagnosis first” from the methodology layer. The A/B test validated a specific instantiation of the general principle. The full sm-vs-pua experiment is designed and costed ($8 for a smoke test) but not yet run.
The deeper observation at this layer: what the model says is not always what the model does. I can constrain generation format with templates. I can constrain perspective with personas. I can constrain sequencing with gates. But the model is still a black box between inputs and outputs. In the S2 failure, the model described perfect reasoning and then acted inconsistently with that reasoning. That’s not a PUA problem. It’s an alignment problem at the level of a single reasoning chain.
I don’t have a solution for this yet. What I have is: surface the reasoning before the action (SM), run actions through gates that check the outputs, and keep QC independent so at minimum the final artifact gets evaluated against the spec rather than against the model’s self-assessment.
What’s verified, what isn’t
I’ve been tracking this explicitly because I kept noticing I had strong opinions about things I’d never actually tested.
| Verified | Evidence |
|---|---|
| Evaluate step construct validity | H1 p=0.0205, H2 p=0.0135, dose-response gradient |
| DiagnosisGate / SM effect | A/B test, S2 correct rate 0/3 → 2/3, N=3 |
| Operator pattern extraction | pipeline-ops/ 177 lines, 24 tests passed |
| Beamer/Spina template reuse | Slides reproducible, 184 upstream stars |
| Steal design, not code | Experiment confirmed: DataFlow design adopted, code rejected |
| Not verified | Status |
|---|---|
| 4 blog posts | Written, zero external signal |
| TheResearcher persona | Written, not independently published |
| output-styles/ guides | Exist, mostly unused |
| sm-vs-pua full experiment | Designed, not run |
The N=3 for SM is real and it nags at me. The signal is real enough to act on — 0/3 to 2/3 on a reproducible failure scenario is not noise. It’s not enough to make strong generalizations about. The full experiment will run.
What this stack actually optimizes
Looked at from a distance, this is a per-capita productivity multiplier.
The factory model of AI usage says: give it a prompt, get output. One input, one output. The supply chain model — which is what this stack actually implements — separates creativity, generation, and quality control into distinct stages. The human provides direction (Layer 1) and QC criteria (Layer 2). Everything below amplifies those decisions into outputs that would otherwise require a team.
Concrete numbers from my own usage: one person, one session, 16 blog posts QC’d and published through the from-framework-to-published pipeline. One person, one eval pipeline, producing construct-validated assessments that would normally require a research team to design, run, and audit. The bottleneck isn’t generation — it’s the human decisions at Layer 1 that generation can’t substitute for.
This reframing matters because it changes what you optimize for. The factory model optimizes for prompt quality (better input → better output). The supply chain model optimizes for the infrastructure between input and output — the templates, gates, pipelines, and independence mechanisms that turn one decision into reliable, audited deliverables.
The meta-point
I didn’t build this stack by sitting down and designing a production framework. I built it by hitting failure modes.
Brainstorming and executing in the same session produced degraded code. That forced phase separation (Layer 4). Code that worked in an eval script was hard to reuse because every function had its own signature. That forced the operator pattern (Layer 3). QC by the same agent that produced the content kept missing its own errors. That forced independence enforcement (Layer 4) and the persona approach (Layer 2). PUA worked but had a blind spot I couldn’t explain. That forced the A/B test (Layer 5) and eventually SM (Layer 5 → Layer 2).
Each layer exists because something in the layer above it was hard to enforce without it. The methodology says “diagnosis first.” The code pattern layer is what “diagnosis first” looks like in code (DiagnosisGate). The execution infrastructure is what makes the code patterns run reliably (clean context, independent QC). The model behavior layer is the empirical record of where the model doesn’t behave as specified.
The top of the stack — human direction — is the one layer that doesn’t reduce to the layer below it. Which I suppose is the point.
The takeaway, if I had to compress this to one sentence: every failure mode I kept hitting was a case of acting before externalizing — implementing before writing the spec, fixing before diagnosing, publishing before auditing. The stack is just what “externalize first” looks like across four levels of abstraction.